
In Innoquest Cohort-1 Class 6, we continued working on building a machine-learning model for predicting absenteeism. This session focused on data preprocessing, encoding, scaling, and analyzing feature importance. While I already had a strong grasp of these concepts, the session provided a refreshing hands-on experience and an opportunity to implement these steps systematically.
This blog post shares my learnings, liked and disliked parts of the session, suggestions for improvement, and a practical case study inspired by today’s activities.
Liked Aspects
- Encoding Techniques for Education Feature
- The approach to encoding education feature was impressive and intuitive. This reinforced my understanding of how to manage categorical variables effectively.
- Managing Data Separation
- The tutor demonstrated clean methods for splitting data into training and testing sets, highlighting good practices in data handling.
- Managing Data Separation
- The tutor demonstrated clean methods for splitting data into training and testing sets, highlighting good practices in data handling.
Challenges Faced
With great respect for the incredible teacher, I would like to share some challenges encountered during this class.
- DataFrame Management Hurdles
- Inefficient management of the dataframe during preprocessing caused confusion while setting things up in this class.
- Integer Conversion
- Boolean columns were not converted to integers immediately after encoding in the previous class, leading to unavoidable complications.
- Missing Export of Processed Dataframe
- The processed dataframe from Class 5 was not exported, making it difficult to reproduce earlier results.
- This created unnecessary challenges in maintaining a consistent workflow.
- Initial Model Selection Misstep
- Despite the target variable being categorical, erroneously Linear Regression was used initially instead of Logistic Regression, causing confusion.
Suggestions for Improvement
To achieve better results and derive meaningful insights, the following points can be considered:
- Enhanced Feature Engineering
- Introduce new features or modify existing ones to optimize the model’s performance and derive more business insights.
- Encoding Optimization
- Experiment with other encoding techniques (e.g., target encoding, frequency encoding) for categorical variables.
- Target Data Refinement
- Address anomalies in the target column, such as rows with unavailable hours exceeding 24.
- Regression Alternatives
- Test regression approaches instead of classification for continuous target predictions.
- Data Augmentation
- Increase the dataset size or synthesize data to improve model accuracy and robustness.
- Hyperparameter Tuning
- Perform grid search or randomized search to fine-tune model parameters for better results.
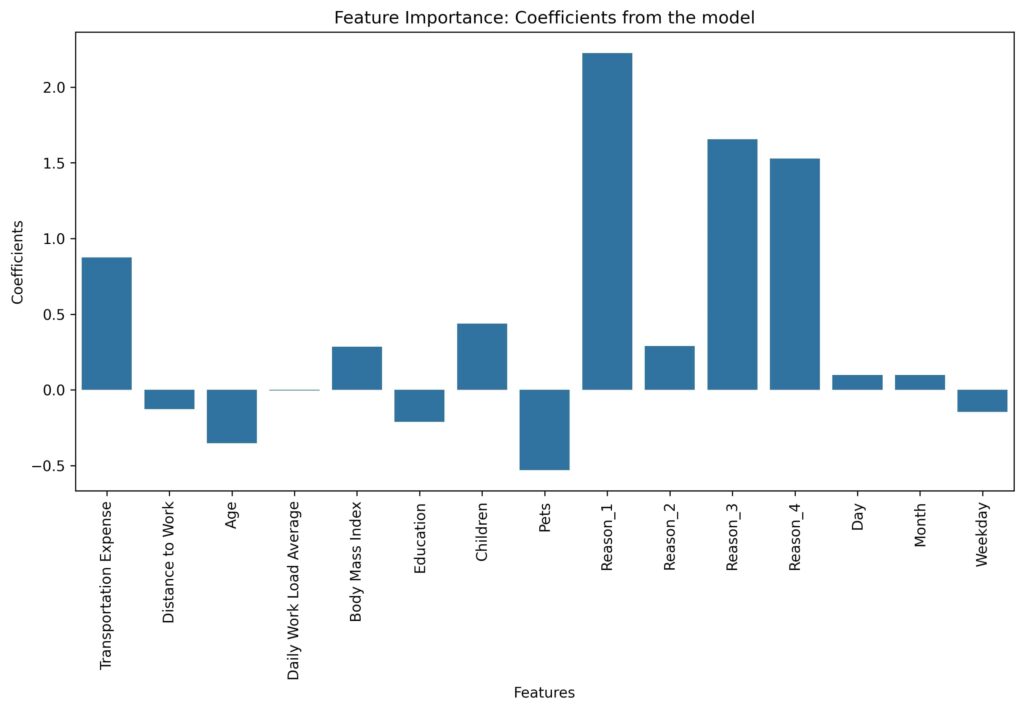
Feature Analysis Chart:
Here is the feature analysis chart I saved during the class. This chart shows the coefficients of the features, helping us identify which factors most influence absenteeism:
A Practical Mindset/Approach: Case Study
Today, I got a new SIM card, which sparked my curiosity about how telecom companies like Jazz, Zong, Telenor, and Ufone decide the free resources they provide (e.g., on-net minutes, off-net minutes, SMS, and MBs) with new SIMs.
Here’s a breakdown of my thought process:
- Resource Allocation Strategies
- Companies might use historical data to determine how much of each resource to allocate to different customer segments (e.g. determine segments by area).
- Customer Usage Analysis
- Monitoring the usage patterns of new customers could help tailor future offers. For instance, a customer with more SMS utilization may receive promotions focused on SMS usage.
- Customer Retention
- Analyzing which of the five possible SIM slots customers tend to fill with competing services may inform strategies to retain or reclaim those customers.
- Targeted Messaging
- Companies can minimize unnecessary marketing efforts by analyzing which customers are likely to purchase new SIMs or additional services based on their usage data.
This approach demonstrates how machine learning models can be applied to optimize business processes and enhance customer satisfaction.
GitHub Repository:
You can find the code for the model, including data preprocessing, encoding, building, feature analysis, and a Streamlit-based application for model inference, all on my GitHub repository. The repository contains detailed instructions for using the model for inference, along with the necessary code to reproduce the results.
Conclusion
The Innoquest Cohort-1 Class 6 session was a refreshing experience that reinforced my existing knowledge while offering practical applications in the real world. The GitHub repository will be a valuable resource for others to replicate, learn from, and build upon.
If you have any suggestions, feel free to contribute to the repository or share your thoughts in the comments.
Great! Good Efforts. Man!
But What about Lec 7!
A.O.A
Good Great Efforts, SHaukat
But you haven’t posted the blod og class 7 and 8, today is 9th class!
A.O.A
Good Great Efforts, Shaukat
But you haven’t posted the blog class 7 and 8, today is 9th class!